

DATA SCIENCE
Internship 2025
Acquire cutting-edge knowledge on the Domain of Data science and put it into practice through an internship program that provides access to industry-leading tools and guidance from experts.
1/ 2 Months
Online
8+ Live Projects
Dual Certification
Ultimate Step towards your Career Goals: Expert in Data Science
Get ahead with the FutureTech Industrial Internship Program: gain hands-on experience, connect with industry leaders, and develop cutting-edge skills. Earn a stipend, receive expert mentorship, and obtain a certificate to boost your career prospects. Transform your future with practical, real-world learning today
Internship Benifits
Mentorship
Receive guidance and insights from industry experts.
Hands-on Experience
Gain practical skills in a real-world cutting-edge projects.
Networking
Connect with professionals and peers in your field.
Skill Development
Enhance your technical and soft skills.
Career Advancement
Boost your resume with valuable experience.
Certificate
Get a certification to showcase your achievements.
Data science Internship Overview
This outline provides a comprehensive roadmap for mastering Python for Data Science, covering essential programming skills, data analysis, machine learning, and practical project applications. Dive in and start transforming data into actionable insights!
Key Highlights:
Understand the fundamentals and significance of data science.
Learn the essentials and advanced aspects of Python programming.
Exploratory Data Analysis (EDA) & Visualization:
- Techniques for analyzing data patterns and creating visual representations
Probability and Statistics for Data Science:
- Learn the foundational concepts of probability and statistics.
Supervised & Unsupervised Learning:
- Supervised Learning: Explore regression and classification models.
- Unsupervised Learning: Discover clustering models.
Tools for Data Visualization:
Tableau: Introduction to Tableau, data sources, and worksheets.
Power BI: Visualize data with various charts, plots, and maps.
Libraries for Data Science:
Pandas: Master data manipulation and analysis.
NumPy: Handle numerical operations and arrays.
Matplotlib: Create data visualizations with plots and graphs.
Seaborn: Generate advanced data visualizations.
Data Science Elements:
Data Collection: Techniques for gathering data.
Data Wrangling & Cleaning: Prepare and clean your data for analysis.
Machine Learning, Data Processing & Feature Engineering:
- Introduction to Machine Learning: Learn concepts and types of learning.
- Preprocessing Data: Prepare data for machine learning models.
- Feature Selection & Engineering: Enhance model performance.
- Handling Missing Data & Outliers: Ensure data integrity.
- Encoding Categorical Variables & Scaling Numerical Variables: Transform your data.
Data Science Project Applications:
Credit Score Classification: Predict credit scores.
Stress Prediction: Analyze stress levels.
Social Media Ads Classification: Classify ads on social media.
Electricity Price Prediction: Forecast electricity prices.
Ground Water Level Prediction: Predict water levels.
Churn Analysis Prediction: Predict customer churn.
Drowsiness Detection Using CNN: Detect driver drowsiness.
Chatbot Creation: Build intelligent chatbots.







Looking for in-depth Syllabus Information? Explore your endless possibilities in DS with our Brochure!
share this detailed brochure with your friends! Spread the word and help them discover the amazing opportunities awaiting them.
Project Submission: Example Output Screenshots from Our Clients
Take a look at these sample outputs crafted by our clients. These screenshots showcase the impressive results achieved through our courses and projects. Be inspired by their work and visualize what you can create!
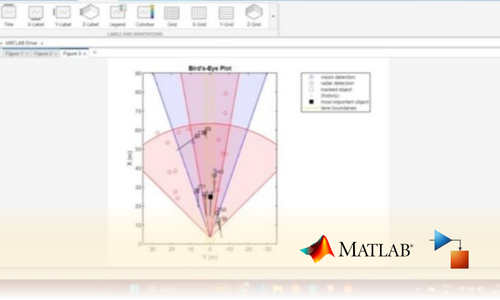
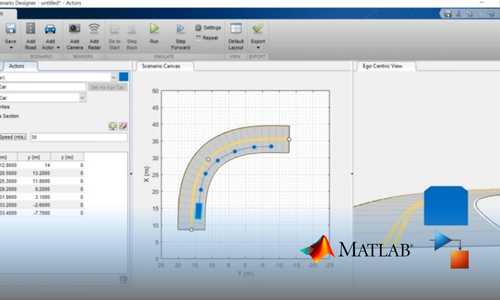
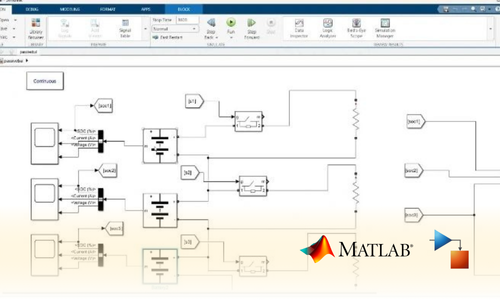
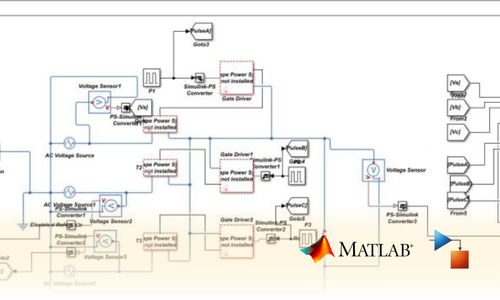
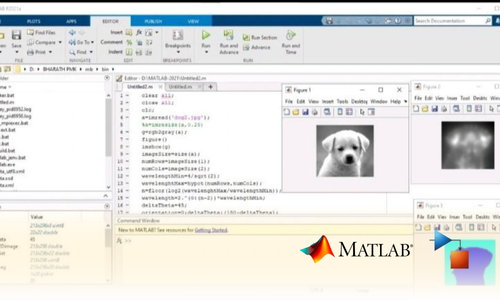
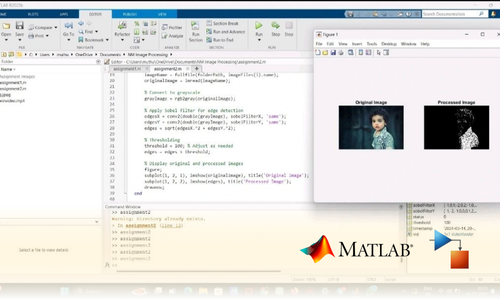
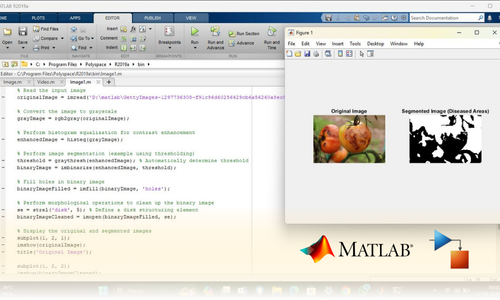



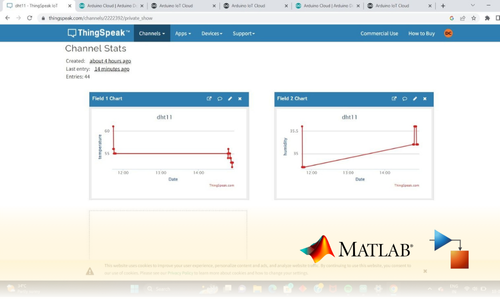
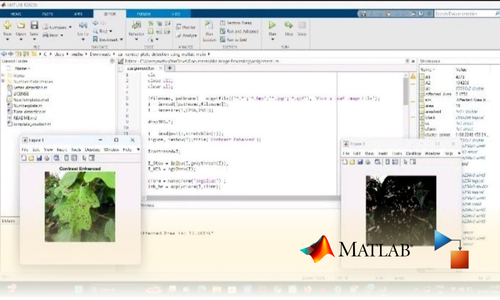
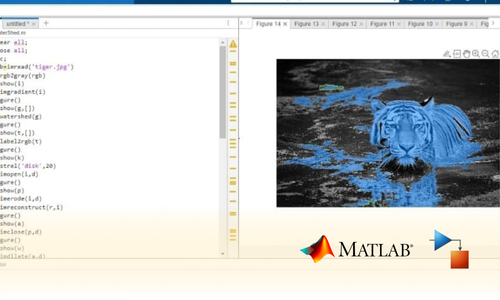
Dual Certification: Internship Completion & Participation
Earn prestigious Dual Certification upon successful completion of our internship program. This recognition validates both your participation and the skills you have honed during the internship


How does this Internship Program Work?
Step 1 Enroll in the Program
- Get a Mentor Assigned
- Presentations & Practice Codes
- Learn at your Flexible Time
- Apprehend the concepts
Step 2 Project Development
- Implement Skills Learn
- Develop Projects with assistance
- Get Codes for Reference
- Visualise the Concepts
Step 3 Get Certified
- Certificate of Internship
- Project Completion Certificate
- Share on social media
- Get Job Notifications
Choose Your Plan fit your needs
Master the Latest Industrial Skills. Select a technology domain & kick off your Internship immediately.
1 Month
₹1999/-
₹999/-
- Internship Acceptance Letter
- 90 Days from the date of payment
- 4 LIVE intractive Mastermind Sessions
- 4+ Capstone Projects & Codes
- Full Roadmap
- Internship Report
- 1 Month Internship Certificate
2 Month
₹3299/-
₹1899/-
- Internship Acceptance Letter
- 180 Days from the date of payment
- 4 LIVE interactive Mastermind Sessions
- 12+ Capstone Projects & Codes
- Full Roadmap
- Internship Report
- Participation Certificate
- 2 Month Internship Certificate
Our Alumni Employers
Curious where our graduates make their mark? Our students go on to excel in leading tech companies, innovative startups, and prestigious research institutions. Their advanced skills and hands-on experience make them highly sought-after professionals in the industry.




EXCELLENTTrustindex verifies that the original source of the review is Google. I recently completed my Python internship under the guidance of Mentor poongodi mam We learnt so many new things that developed my knowledge.this experience is good to learnTrustindex verifies that the original source of the review is Google. I completed my python internship guidance of mentor poongodi mam. She thought us in friendly qayTrustindex verifies that the original source of the review is Google. Poongodi mam done very well She took the class very well When we ask any doubt without getting bored she will explain,we learned so much from mam,marvelousTrustindex verifies that the original source of the review is Google. I have handled by poongodi mam.domain python intership...was goodTrustindex verifies that the original source of the review is Google. I recently completed Python internship under the guidance of poongodi mam who excelled in explaining concepts in an easily understandable wayTrustindex verifies that the original source of the review is Google. Fantastic class we were attended..we got nice experience from this class..thank you for teaching python mam...Trustindex verifies that the original source of the review is Google. -The course content was well-structured - I gained valuable insights into microcontrollers, sensors, and programming languages- The workshop was informative, interactive, and challenging, pushing me to think creatively. Ms Jimna our instructor her guidance and feedback helped me overcome obstacles and improve my skills.Trustindex verifies that the original source of the review is Google. The learning experience was really worth since more than gaining just the knowledge all of the inputs were given in a friendly and sportive manner which then made it a good place to learn something with a free mindset... 👍🏻Trustindex verifies that the original source of the review is Google. I recently completed my full stack python intership under the guidance of mentor Gowtham,who excelled in explaining concepts in an easily understand mannerTrustindex verifies that the original source of the review is Google. Gowtham-very interesting class and I learning so many things in full stack python development and I complete my internship in Pantech e learning and it is useful for my career
FAQ
How do I get started in Data Science?
To get started in Data Science:
- Learn Python or R: These are the two most popular programming languages used in the field.
- Master Key Libraries: Learn libraries like Pandas, NumPy, and Scikit-learn for Python, or dplyr, ggplot2, and caret for R.
- Learn Statistics: A solid understanding of statistics is essential for hypothesis testing, regression analysis, and model evaluation.
- Take Online Courses: Platforms like Coursera, edX, and Udacity offer excellent courses in Data Science and Machine Learning.
- Practice on Real Datasets: Use platforms like Kaggle to practice on real-world problems and improve your skills.
- Work on Projects: Build a portfolio by solving real-world problems and sharing your projects on GitHub or personal websites.
What is the difference between AI, Machine Learning, and Deep Learning?
Artificial Intelligence (AI): A broad field focused on creating intelligent agents or systems that can simulate human behavior and decision-making. AI includes everything from rule-based systems to advanced machine learning models.
Machine Learning (ML): A subset of AI that involves algorithms that allow systems to learn from data and improve over time without being explicitly programmed.
Deep Learning (DL): A specialized area of machine learning that uses deep neural networks (DNNs) to model complex patterns and structures in large datasets, particularly useful for tasks like image recognition, speech recognition, and natural language processing.
What is the difference between supervised and unsupervised learning?
Supervised Learning: Involves training a model on a labeled dataset, where the input data is paired with the correct output. The goal is to predict or classify new data based on this training. Examples include:
- Regression: Predicting continuous values (e.g., house price prediction).
- Classification: Categorizing data into classes (e.g., spam detection).
Unsupervised Learning: Involves training a model on data that has no labels. The goal is to find patterns, groupings, or structures in the data. Examples include:
- Clustering: Grouping similar data points (e.g., customer segmentation).
- Dimensionality Reduction: Reducing the number of features in data while retaining important information (e.g., PCA).
What are some common Data Science techniques?
- Supervised Learning: Where the model is trained on labeled data (e.g., regression, classification).
- Unsupervised Learning: Finding hidden patterns or intrinsic structures in data without labeled outcomes (e.g., clustering, dimensionality reduction).
- Deep Learning: A type of machine learning that uses neural networks to model complex patterns in large datasets (e.g., CNNs, RNNs).
- Natural Language Processing (NLP): Techniques for analyzing and modeling textual data (e.g., sentiment analysis, topic modeling).
- Reinforcement Learning: Where agents learn by interacting with an environment to maximize cumulative rewards.
What tools are commonly used in Data Science?
Some common tools used in Data Science are:
- Programming Languages: Python, R
- Libraries/Frameworks:
- Python: Pandas, NumPy, Matplotlib, Seaborn, Scikit-learn, TensorFlow, Keras, PyTorch
- R: dplyr, ggplot2, caret, shiny
- Databases: MySQL, PostgreSQL, MongoDB, and NoSQL databases
- Big Data: Hadoop, Spark
- Cloud Platforms: AWS, Google Cloud, Microsoft Azure
- Data Visualization: Tableau, Power BI, Plotly
- Data Processing: Apache Kafka, Apache Airflow
What are the steps in the Data Science workflow?
The general workflow of a Data Science project typically includes the following steps:
- Problem Definition: Understanding and framing the problem you’re trying to solve.
- Data Collection: Gathering data from various sources (databases, APIs, web scraping, etc.).
- Data Cleaning: Preprocessing the data to handle missing values, outliers, and incorrect data.
- Exploratory Data Analysis (EDA): Visualizing and analyzing the data to uncover patterns, trends, and relationships.
- Feature Engineering: Creating new features or modifying existing ones to improve the model’s performance.
- Model Building: Selecting and training machine learning models or statistical methods on the data.
- Model Evaluation: Assessing the performance of the model using metrics such as accuracy, precision, recall, F1 score, and cross-validation.
- Deployment: Deploying the model into production for real-world use (optional for some projects).
- Monitoring & Maintenance: Regularly updating the model and monitoring performance over time.
Start Your Tech Journey Today
Sign Up for Exclusive Resources and Courses Tailored to Your Goals!

© 2025 pantechelearning.com